Fr, 11.09.2015 - 14:46 — Peter Schuster 
![]() Wissenschaftliches Rechnen (computational science) ist neben Theorie und Experiment zur dritten Säule naturwissenschaftlicher Forschung geworden. Computer-Modelle erlauben Gesetzmäßigkeiten komplexer unerforschter Systeme zu entdecken, Vorhersagen für komplexe dynamische Systeme zu erstellen und reale Vorgänge in einer Präzision zu simulieren, die experimentell erreichbare Genauigkeiten bereits übertreffen kann. Der theoretische Chemiker Peter Schuster ist seit den frühen 1960er Jahren auf dem Gebiet der Modellierungen tätig. An Hand einiger typische Beispiele zeigt er hier Wert und Aussagefähigkeit von Computer-Modellen auf.*
Wissenschaftliches Rechnen (computational science) ist neben Theorie und Experiment zur dritten Säule naturwissenschaftlicher Forschung geworden. Computer-Modelle erlauben Gesetzmäßigkeiten komplexer unerforschter Systeme zu entdecken, Vorhersagen für komplexe dynamische Systeme zu erstellen und reale Vorgänge in einer Präzision zu simulieren, die experimentell erreichbare Genauigkeiten bereits übertreffen kann. Der theoretische Chemiker Peter Schuster ist seit den frühen 1960er Jahren auf dem Gebiet der Modellierungen tätig. An Hand einiger typische Beispiele zeigt er hier Wert und Aussagefähigkeit von Computer-Modellen auf.*
Bis in die zweite Hälfte des vorigen Jahrhunderts schritten die Naturwissenschaften auf zwei Beinen voran – auf der Theorie und auf dem Experiment. Dies waren auch die beiden Säulen, auf denen Karl Popper 1935 seine Erkenntnistheorie der modernen Naturwissenschaft, die „Logik der Forschung“ aufbaute. Auf eine kurze Formel gebracht, besagt diese:
- etablierte Theorien spiegeln den aktuellen Stand der Naturwissenschaften wider,
- neue experimentelle Daten falsifizieren die Theorien,
- daraus erwachsen neue Theorien, welche in der Lage sind die neuen Befunde zusammen mit dem vormaligen Wissensstand zu erklären.
Für Poppers Erkenntnistheorie gibt es zwei klassische Paradebeispiele: i) Einsteins Relativitätstheorie und ii)die Quantenmechanik.
Eine dritte Säule der Forschung
Als Mitte des 20. Jahrhunderts die ersten elektronischen Rechner aufkamen, änderte sich die Situation – das wissenschaftliche Rechnen betrat die Bühne der Forschung und spielt seitdem entscheidend mit. Die frühen Computer boten allerdings noch sehr bescheidene Möglichkeiten, sie waren äußerst langsam, die Speicherkapazitäten sehr begrenzt. Dementsprechend konnten damals nur sehr einfache Modelle und das auch nur „so ungefähr“ behandelt werden; über die daraus getätigten Prognosen rümpfte jeder hartgesottene Experimentator die Nase.
Seitdem haben sich die elektronischen Rechenanlagen mit atemberaubendem Tempo weiterentwickelt und es liegt heute eine völlig veränderte Situation vor. Wissenschaftliches Rechnen (computational science) ist zur dritten Säule, zum fest etablierten Werkzeug der Forschung geworden. Der enorme Zuwachs zu unserem Wissensstand fußt auf dieser Säule. Nichtsdestoweniger gibt es auf einigen Gebieten Fehlschlüsse und falsche Erwartungen, die in die Aussagefähigkeit der Ergebnisse von Computer-Modellen gesetzt werden. Einige von den allgemeinen Schwierigkeiten sollen im Folgenden beleuchtet werden.
Modelle basieren auf Vereinfachungen
Vorausschicken möchte ich zwei Zitate: i) die moderne, üblicherweise Einstein zugeschriebene Version von Ockhams Razor: „Alles sollte so einfach wie möglich gemacht werden, aber nicht einfacher“ und ii) die Charakterisierung von Modellen durch den amerikanischen Statistiker George Box: „Alle Modelle sind falsch, aber einige sind nützlich.“
 Abbildung 1. Wilheln von Ockham. Das nach diesem Mönch benannte erkenntnistheoretische Prinzip „Occam’s Razor“ hat dieser nie so formuliert, wohl aber dem Sinn nach in seinen Schriften verwendet. (Quelle: Wikipedia;. aus Ockham's Summa Logicae, 1341)
Abbildung 1. Wilheln von Ockham. Das nach diesem Mönch benannte erkenntnistheoretische Prinzip „Occam’s Razor“ hat dieser nie so formuliert, wohl aber dem Sinn nach in seinen Schriften verwendet. (Quelle: Wikipedia;. aus Ockham's Summa Logicae, 1341)
Um praktisch anwendbar sein zu können, müssen Theorien und Modelle die Natur vereinfachen. Dabei erhebt sich die Frage, wieweit eine Vereinfachung noch zulässig ist, ohne dass dabei die eigentliche Aussage verzerrt wird. Es ist trivial, wird aber häufig vergessen: die Zulässigkeit von Vereinfachungen hängt stark vom Kontext ab, in dem das Modell angewandt werden soll. Dies mag das folgende Beispiel erläutern:
Newtons Gravitationsgesetze gelten korrekt in der Himmelsmechanik solange relativistische Effekte vernachlässigbar klein sind. Im Alltag wird ein Fehler des Newtonschen Gesetzes aber sofort augenfällig, wenn man zu Boden fallende Körper beobachtet und die Ursache dafür sind definitiv nicht relativistische Effekte. Sieht man, wie ein Papierblatt, eine Feder und ein Stein zu Boden fallen, erscheint die Voraussage, dass alle Körper gleich schnell fallen, absurd. Der Fehler liegt in der Vernachlässigung des Luftwiderstands, der – in der Himmelsmechanik nicht existent – im Kontext der Erdatmosphäre das Modell zu stark vereinfacht hat.
In diesem Sinne erscheint es angebracht die oben erwähnte Aussage von George Box umzuformulieren:
„Zwangsläufig sind alle Modelle falsch, denn ohne Vereinfachungen sind sie unbrauchbar, aber mit Vereinfachungen wird es immer Umstände geben, unter denen diese zu komplett falschen Vorhersagen führen.“
Es ist die hohe Kunst erfolgreicher Modellierungen, dass die Vereinfachungen auf den Kontext abgestimmt werden, unter denen das Modell angewendet werden soll. In den Naturwissenschaften wird vorausgesetzt, dass Modelle validiert sind oder zumindest validiert werden können. Dies ist nicht immer der Fall in Politik oder bei Systemanalysen – unter gewissen Vorsichtsmaßnahmen erscheint es hier aber legitim auch unzureichend validierte Modelle anzuwenden.
Modell ist nicht gleich Modell
Entsprechend ihren Zielen lassen sich Modelle in 3 Typen einteilen:
1. Exploratorische Modelle. Der Informatiker Steve Banks definiert diese knapp und präzise als „eine Forschungsmethode, die Computer-Simulationen benutzt, um komplexe und unbekannte Systeme zu analysieren“. Der Zweck exploratorischer Modelle ist es daher neue Gebiete für die wissenschaftliche Forschung zu erkunden und vorzubereiten. Das primäre Ziel ist es Gesetzmäßigkeiten zu entdecken, nicht aber Vorhersagen zu machen.
2. Prädiktive Modelle. Diese basieren auf bereits gesicherten wissenschaftlichen Grundlagen und werden erstellt, um Voraussagen für zukünftige Entwicklungen zu erhalten. Im Allgemeinen sind die Informationen über ein System aber unvollständig und komplexe Dynamik und chaotisches Verhalten fügen noch weitere Unsicherheiten dazu. Die Vorhersagekraft eines derartigen Modells hängt daher sowohl von der Qualität der vorhandenen Daten als auch von der Verlässlichkeit des Modells ab.
3. Präzise Simulation. Diese dritte Klasse rechnerischer Modelle strebt an, experimentelle Daten präzise simulieren/reproduzieren zu können. Quantitative Eigenschaften werden hier mit hoher Genauigkeit bestimmt, entsprechen den genauesten experimentellen Messungen oder übertreffen diese sogar.
Validierung und Verifizierung
Alle rechnerischen Modelle werden dem Prozess der Validierung und Verifizierung unterworfen (oder sollten dies zumindest werden). Die Validierung bestimmt dabei inwieweit das Modell das reale System aus der Perspektive der beabsichtigten Anwendungen widergeben kann. Die Verifizierung prüft die Qualität der Aussagen des Modells, beispielsweise den Grad korrekter Aussagen.
Im Folgenden sollen einige typische Beispiele für diese drei Klassen an Modellen in Physik, Chemie, Ingenieurwissenschaften und Lebenswissenschaften aufgezeigt werden.
Ursprung des Lebens – ein Fall für das Design exploratorischer Modelle (Typ 1)
Überflüssig darauf hinzuweisen: in diesem Forschungsgebiet ist das zu modellierende System sowohl komplex als auch durch unsichere und unvollständige Daten charakterisiert. Ein typisches Beispiel dafür ist das sogenannte GARD-Modell (graded autocatalysis replication domain), das Doron Lancet (Weizmann Institute of Science, Rehovot) entwickelt hat.
Lancet beschäftigt sich mit der Frage, wie kleine Moleküle – solche, die unter präbiotischen Bedingungen entstehen konnten - spontan Aggregate (er bezeichnet diese als „Composome“) bilden, ihre chemische Information weitergeben und einem Selektions-und Evolutionsprozess unterliegen können. Soweit es die Rechnungen betrifft, hat das Modell eine solide mathematische Basis: Differentialgleichungen zur Beschreibung der autokatalytischen Aggregationsprozesse, stochastische Simulationen für den Selektions-/Evolutionsprozess. Allerdings fehlen Versuchsanordnungen, welche die rechnerischen Ergebnisse experimentell verifizieren könnten. Validation und Verifikation des Modells beziehen sich nur auf dessen interne Konsistenz und die nummerische Richtigkeit der Berechnungen. Nichtsdestoweniger können auf dieser Basis wichtige Eigenschaften des Modells diskutiert werden, beispielsweise ob derartige Composome überhaupt einen Evolutionsprozess durchlaufen können.
Wettervorhersage – ein bestens untersuchtes und populäres prädiktives Modell (Typ 2)
In diesem Fall sind beide Voraussetzungen für ein prädiktives Modell erfüllt: i) die Dynamik der Atmosphäre basiert auf der Physik von Flüssigkeiten und ist wohlverstanden, und ii) eine Unmenge an empirischen Daten wird täglich erhoben. Dies geschieht aus leicht nachvollziehbaren Gründen: eine verlässliche Wettervorhersage stellt ja einen enorm wichtigen Faktor in der globalen Ökonomie, Soziologie und im Katastrophenmanagement dar.
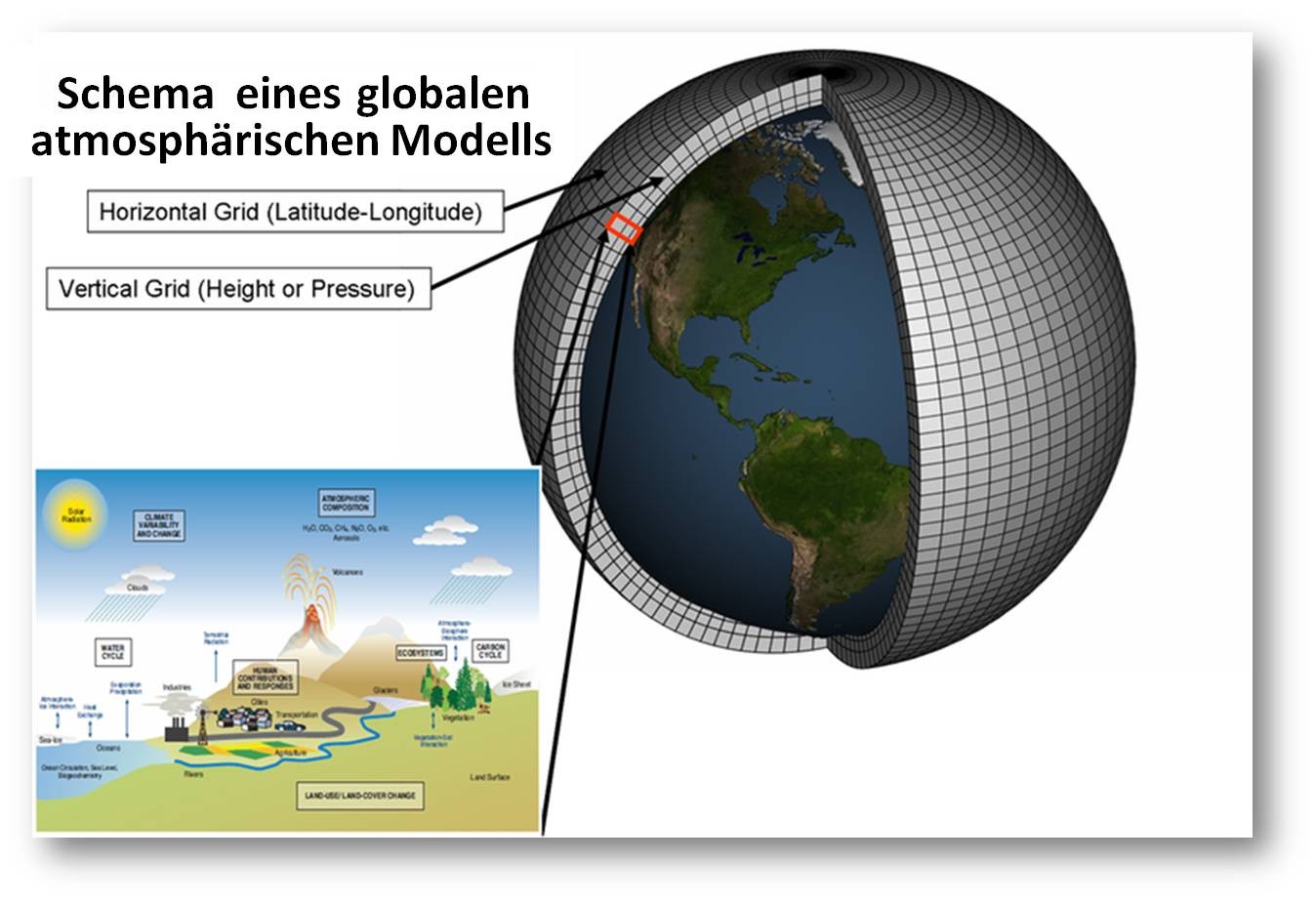 Abbildung 2. Wetter(Klima)vorhersagen sind prädiktive Modelle. Sie basieren auf etablierten physikalischen/chemischen Gesetzen. Die Erde wird in ein dreidimensionales Gitter eingeteilt und die atmosphärischen/terrestrischen Prozesse in jedem Abschnitt und in den Wechselwirkungen benachbarter Abschnitte modelliert. (Bild: Wikipedia; NOAA)
Abbildung 2. Wetter(Klima)vorhersagen sind prädiktive Modelle. Sie basieren auf etablierten physikalischen/chemischen Gesetzen. Die Erde wird in ein dreidimensionales Gitter eingeteilt und die atmosphärischen/terrestrischen Prozesse in jedem Abschnitt und in den Wechselwirkungen benachbarter Abschnitte modelliert. (Bild: Wikipedia; NOAA)
Nichtsdestoweniger bleiben Ungewissheiten zurück und die Vorhersage beruht auf Wahrscheinlichkeitsannahmen. Für diese Unsicherheiten gibt es zwei wesentliche Gründe: i) die Erdoberfläche weist eine zu komplizierte klein- und mittelräumige Strukturierung auf, als dass dies mir ausreichender Genauigkeit berücksichtigt werden könnte, und ii) die Dynamik von Flüssigkeiten nimmt bereits bei mäßigen Geschwindigkeiten einen turbulenten Verlauf - dies führt zu den all den Problemen, die mit einer Vorhersage bei einem deterministischen Chaos einhergehen.
Versuche das Wetter auf der Basis von Berechnungen vorherzusagen, nahmen bereits im frühen 20. Jahrhundert ihren Anfang. Die Daten dazu kamen ausschließlich von der Erdoberfläche und von Wetterballons, die rechnerischen Möglichleiten waren bescheiden. Effektive Rechner-basierte Vorhersagen starteten 1966 in Westdeutschland und den US, England folgte 1972, Australien 1977. Seitdem ist die Geschwindigkeit der Computer enorm gestiegen und noch wesentlich mehr hat sich die Effizienz der Algorithmen verbessert. Sicherlich gibt es hier noch weitere Steigerungsmöglichkeiten. Dennoch bleiben die oben genannten Einschränkungen – Turbulenzen in der Atmosphäre, komplizierte kleinräumige Strukturierung der Erdoberfläche – bestehen und Wettervorhersagen werden auch weiterhin auf Wahrscheinlichkeitsannahmen beruhen.
Quantenchemie – präzise Simulation chemischer Problemstellungen (Typ 3)
Simulationsmodelle bauen auf physikalischen Gesetzen oder auf etablierten empirischen Gesetzmäßigkeiten auf. Wie erwähnt erreichen derartige Modelle eine numerische Präzision, die sogar über die der experimentell en Messungen hinausgehen kann.
Die Quantenchemie - die Anwendung der Quantenmechanik auf chemische Problemstellungen – blieb bis in die 1960er Jahre weitgehend chancenlos. Es fehlten ja ausreichend große Rechnerkapazitäten und man setzte grobe Näherungsmethoden ein, um Lösungen der Schrödingergleichung für Moleküle zu finden. Diese waren so ungenau, dass sie von Experimentatoren bestenfalls milde belächelt wurden. Chemiker rasteten aus als Paul Dirac – Mitbegründer der Quantenphysik und Nobelpreisträger konstatierte:
„Die zugrundeliegenden physikalischen Gesetze, die für die mathematische Theorie eines großen Teils der Physik und der gesamten Chemie benötigt werden, sind vollständig bekannt. Die Schwierigkeit besteht ausschließlich darin, dass eine präzise Anwendung dieser Gesetze zu Gleichungen führt, die für Lösungen viel zu kompliziert sind. Es wird daher wünschenswert praktische Näherungsmethoden zur Anwendung der Quantenmechanik zu entwickeln, die – ohne ein Übermaß an Rechnerleistung - zu einer Erklärung der wesentlichen Eigenschaften komplexer atomarer Systeme führen.“
Tatsächlich erfüllte sich Diracs Traum sechsachtzig Jahre später. Moleküle mit nicht zu vielen Atomen und im idealen Festkörperzustand können nun berechnet werden. Allerdings: der im Nebensatz geäußerte Wunsch „ohne ein Übermaß an Rechnerleistung“ erfüllte sich nicht. Die für die numerische Quantenmechanik benötigte Rechnerleistung ist enorm hoch. 1998 wurden Walter Kohn und John Pople mit dem Nobelpreis ausgezeichnet für „die Entwicklung von Rechenverfahren, die Näherungslösungen der Schrödingergleichungen für Moleküle und Kristalle erzielen“. Heute werden die meisten spektroskopischen Eigenschaften von kleinen Molekülen berechnet: dies ist einfacher und genauer als die experimentalle Bestimmung.
Computational Mechanics – präzise Simulierungen im Bauingenieurwesen (Typ 3)
diese neue Fachrichtung beschäftigt sich mit einer enormen Vielfalt von Problemen, die in verschiedensten Ingenieurbereichen auftreten (beispielsweise in Strömungslehre, Statik und Materialwissenschaften). Um nur einige Anwendungen herauszugreifen:
- Im Flugzeugbau reduziert die Simulation von Windkanälen die Anzahl realer Experimente und erspart damit Millionen Dollars.
- Modelle, die Materialwissenschaften und Statik kombinieren, lösen Konstruktionsprobleme vom Errichten von Gebäuden über den Brückenbau zum Tunnelbau (ei n Beispiel ist hier die Berechnung der Strukturen von Beton). Ein besonders spektakulärer Erfolg ist der Rechner-unterstützte Abbruch alter Bauwerke.
- Schlussendlich ist auch das große Gebiet der Industriemathematik zu erwähnen, das ausgefeilte mathematische Modelle und Computer-Simulationen anwendet, um Optimierungsprobleme in Industrieverfahren zu lösen. Ein Beispiel ist die Bestimmung der Temperaturprofile im Innern von Hochöfen.
Schlussfolgerungen - Ausblick
An Hand einiger willkürlich herausgegriffener Beispiele wird offensichtlich, wie interdisziplinär einsetzbar wissenschaftliche Modellierung und Simulation sind. Ausgezeichnete Ergebnisse in Physik, Chemie und Technik machen wissenschaftliches Rechnen zum unentbehrlichen Werkzeug in diesen Fächern. Darüber hinaus findet man Anwendungen des Rechner-unterstützten Modellierens im nahezu gesamten Spektrum aller Disziplinen: in der Theoretischen Ökonomie ebenso wie in der Soziologie, in den Lebenswissenschaften und auch in Medizin und der Pharmakologie – um nur einige Beispiel zu nennen.
Wissenschaftliches Rechnen ist tatsächlich zu einer dritten Säule geworden, gleichberechtigt mit Theorie und Experiment in Physik, Chemie und Technik. In den Lebenswissenschaften und in weiteren Disziplinen ist die Einstellung zu Computermodellen allerdings eine andere. Die Modell-basierte Theoretische Biologie hat einen schlechten Ruf bei experimentell arbeitenden Biologen ebenso wie bei Mathematikern.
Warum ist dies so? Die Gründe sind mannigfach:
einer davon ist zweifellos die inhärente Komplexität lebender Systeme, die bedingt, dass ein Großteil der Modelle exploratorischen Charakter hat. Man sollte nie vergessen, dass das Ziel exploratorischer Modelle die Entdeckung von Gesetzmäßigkeiten in den untersuchten Vorgängen ist und dass dies ein sehr wertvolles Ziel in unbekanntem Neuland darstellt. Meiner Meinung nach werden viele dieser exploratorischen Modelle oft falsch interpretiert und als prädiktiv missbraucht. Hier gilt: Falsche Prognosen sind schlimmer als keine Prognosen!
Ein zweiter Grund für den schlechten Ruf ist eher von psychologischer Art. Theoretische Biologen tendieren häufig dazu ihre Modelle über deren Wert zu verkaufen. Wenn beispielsweise ein Forscher eine interessante Regelmäßigkeit bei einem irregulären Zellwachstum errechnet hat, so verkündet er üblicherweise, dass er das Krebsproblem gelöst hat. Man sollte sich hier an ein Faktum halten, das zwar trivial ist, häufig aber übersehen wird und das (sinngemäß übersetzt) der britische Chemiker und Lesley Orgel so kommentiert:
„Wenn wir nahezu nichts über einen Term in einer Kette wissen, so wissen wir auch nahezu nichts über die Summe der Terme, auch, wenn wir die Werte der übrigen Terme kennen.“
Literatur
(unvollständige Liste) Popper, K. Logik der Forschung. Zur Erkenntnistheorie der modernen Naturwissenschaft. Verlag von Julius Springer, Wien 1935.
Box, G.E.P., Draper, N.R. Empirical model-building and response surfaces. John Wiley & Sons. Hoboken, NJ 1987. Bankes, S. Exploratory modeling for policy analysis. Operations Research, 1993, 41, 435-449.
Segré, D., Ben-Eli, D., Lancet, D. Compositional genomes: Prebiotic information transfer in mutually catalytic noncovalent assemblies. Proc.Natl.Acad.Sci.USA, 2000, 97, 4112-4117.
Orgel, L.E. The origin of life – How long did it take? Orinigs of Life and Evolution of the Biosphere, 1998, 28, 91-96.
*Die (leicht unterschiedliche) englische Version des Artikels ist eben in der Zeitschrift Complexity erschienen, deren Herausgeber der Autor ist. Dort ist auch eine vollständige Liste der Literaturangeben zu finden. Die meisten der zitierten Arbeiten sind allerdings nicht frei zugänglich, können aber auf Wunsch zugesandt werden Peter Schuster. Models – From exploration to prediction. Bad reputation of modeling in some disciplines results from nebulous goals. Complexity, Article first published online: 9 SEP 2015 | DOI: 10.1002/cplx.21729
Weiterführende Links
- Walter Kohn, John A. Pople. About the Nobel price in Chemistry 1998.
- John A. Pople (1998) Quantum Chemical Models , Nobel lecture. (PDF-Download)
- Wettervohersagemodelle der ZAMG
- Science Education: Computers in Biology. Website des NIH mit sehr umfangreichen, leicht verständlichen Darstellungen (englisch) http://publications.nigms.nih.gov/order/computers-biology.html
Artikel von Peter Schuster zu verwandten Themen im ScienceBlog
- Printer-friendly version
- Log in to post comments